NPTEL Introduction To Machine Learning Week 1 Assignment Answer 2023
admin
27 Jul, 2023
Welcome to the world of machine learning! NPTEL's Introduction to Machine Learning course is designed to provide you with a solid foundation in this exciting field. As part of the course, you will encounter various assignments that test your understanding and knowledge of the subject matter. One such critical assignment is NPTEL Introduction to Machine Learning Assignment Answer 2023. In this article, we will dive deep into the intricacies of the assignment, exploring its key concepts and providing valuable insights to help you succeed.
NPTEL Introduction To Machine Learning Week 1 Assignment Answer 2023
In the NPTEL Introduction to Machine Learning course, the Assignment Answer 2023 is a crucial component that assesses your comprehension and problem-solving abilities related to machine learning topics. This assignment is designed to challenge your analytical thinking and application of machine learning algorithms to real-world scenarios.
1.Which of the following is a supervised learning problem?
Grouping related documents from an unannotated corpus.
Predicting credit approval based on historical data.
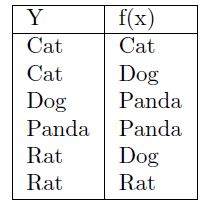
Predicting if a new image has cat or dog based on the historical data of other images of cats and dogs, where you are supplied the information about which image is cat or dog.
Fingerprint recognition of a particular person used in biometric attendance from the fingerprint data of various other people and that particular person.
2.Which of the following are classification problems?
Predict the runs a cricketer will score in a particular match.
Predict which team will win a tournament.
Predict whether it will rain today.
Predict your mood tomorrow.
3.Which of the following is a regression task?
Predicting the monthly sales of a cloth store in rupees.
Predicting if a user would like to listen to a newly released song or not based on historical data.
Predicting the confirmation probability (in fraction) of your train ticket whose current status is waiting list based on historical data.
Predicting if a patient has diabetes or not based on historical medical records.
Predicting if a customer is satisfied or unsatisfied from the product purchased from ecommerce website using the the reviews he/she wrote for the purchased product.
4.Which of the following is an unsupervised learning task?
Group audio files based on language of the speakers.
Group applicants to a university based on their nationality.
Predict a student’s performance in the final exams.
Predict the trajectory of a meteorite.
5.Which of the following is a categorical feature?
Number of rooms in a hostel.
Gender of a person
Your weekly expenditure in rupees.
Ethnicity of a person
Area (in sq. centimeter) of your laptop screen.
The color of the curtains in your room.
Number of legs an animal.
Minimum RAM requirement (in GB) of a system to play a game like FIFA, DOTA.
6.Which of the following is a reinforcement learning task?
Learning to drive a cycle
Learning to predict stock prices
Learning to play chess
Leaning to predict spam labels for e-mails
7.Let X and Y be a uniformly distributed random variable over the interval [0,4] and [0,6] respectively. If X and Y are independent events, then compute the probability, P(max(X,Y)>3)
1/6
5/6
2/3
1/2
2/6
5/8
None of the above
8.Find the mean of 0-1 loss for the given predictions:
1
0
1.5
0.5
9.Which of the following statements are true? Check all that apply.
A model with more parameters is more prone to overfitting and typically has higher variance.
If a learning algorithm is suffering from high bias, only adding more training examples may not improve the test error significantly.
When debugging learning algorithms, it is useful to plot a learning curve to understand if there is a high bias or high variance problem.
If a neural network has much lower training error than test error, then adding more layers will help bring the test error down because we can fit the test set better.
10. Bias and variance are given by:
E[f^(x)]−f(x),E[(E[f^(x)]−f^(x))2]
E[f^(x)]−f(x),E[(E[f^(x)]−f^(x))]2
(E[f^(x)]−f(x))2,E[(E[f^(x)]−f^(x))2]
(E[f^(x)]−f(x))2,E[(E[f^(x)]−f^(x))]2
Understanding the Basics of Machine Learning
Before we dive into the assignment, it is essential to grasp the fundamentals of machine learning. LSI Keywords: supervised learning, unsupervised learning, regression, classification.
Question 1: What is Supervised Learning?
Supervised learning is a machine learning technique where the algorithm is trained on a labeled dataset to make predictions. The model learns from historical data and uses it to predict outcomes for new, unseen data. In this approach, the algorithm is provided with inputs and corresponding correct outputs during training.
Question 2: Explain Unsupervised Learning
Unsupervised learning is another category of machine learning, where the algorithm works with an unlabeled dataset. The objective is to find hidden patterns or structures in the data without any predefined labels. The algorithm clusters similar data points together, allowing insights into the underlying relationships.
Question 3: Differentiate Regression and Classification
Regression and classification are two common types of supervised learning. Regression predicts continuous numerical values, while classification assigns data into predefined categories. For example, predicting house prices based on features like square footage is a regression problem, while classifying emails as spam or not spam is a classification problem.
Introduction to Python for Machine Learning
Python is a powerful programming language commonly used in the field of machine learning. LSI Keywords: Python libraries for machine learning, NumPy, Pandas, scikit-learn.
Question 4: Which Python Libraries are Essential for Machine Learning?
When working with machine learning in Python, several libraries are vital for efficient data manipulation and model building. Some essential libraries include NumPy for numerical computations, Pandas for data manipulation, and scikit-learn for various machine learning algorithms.
Data Preprocessing and Feature Engineering
Data preprocessing and feature engineering are crucial steps in preparing the data for machine learning models. LSI Keywords: data cleaning, data normalization, feature selection.
Question 5: What is Data Cleaning?
Data cleaning involves the process of identifying and rectifying errors, inconsistencies, and inaccuracies in the dataset. It ensures the data is of high quality and free from any noise that could negatively impact model performance.
Question 6: Why is Data Normalization Important?
Data normalization scales numerical features to a standard range, usually between 0 and 1. It is crucial for machine learning algorithms that are sensitive to the magnitude of features, ensuring fair representation for all variables.
Question 7: How to Perform Feature Selection?
Feature selection involves choosing the most relevant and informative features from the dataset. It helps reduce model complexity, improve training time, and enhance overall performance.
Building and Evaluating Machine Learning Models
The process of building and evaluating machine learning models is a critical phase in the assignment. LSI Keywords: training and testing, model evaluation metrics.
Question 8: What is the Training and Testing Process?
The training and testing process is fundamental in machine learning. The dataset is split into a training set to train the model and a testing set to evaluate its performance on unseen data.
Question 9: Which Metrics are Used to Evaluate Models?
Various evaluation metrics assess the performance of machine learning models. Common metrics include accuracy, precision, recall, F1 score, and ROC-AUC, depending on the nature of the problem.
Model Selection and Hyperparameter Tuning
Selecting the right model and fine-tuning its hyperparameters significantly impact the model's performance. LSI Keywords: overfitting, cross-validation.
Question 10: What is Overfitting, and How to Avoid It?
Overfitting occurs when a model performs exceptionally well on the training data but fails to generalize on unseen data. To avoid overfitting, techniques like cross-validation and regularization are employed.
Question 11: How to Choose the Best Model?
Choosing the best model involves considering various factors such as the problem's nature, dataset size, and model complexity. It often requires experimentation with different algorithms and selecting the one with the best performance.
Introduction to Neural Networks and Deep Learning
Neural networks and deep learning have revolutionized the field of machine learning, enabling complex pattern recognition and decision-making capabilities.
Question 12: What are Neural Networks?
Neural networks are a class of algorithms inspired by the human brain's structure and functioning. They consist of interconnected nodes or neurons that process and pass information to make predictions.
Question 13: What is Deep Learning?
Deep learning is a subfield of machine learning that involves neural networks with multiple hidden layers. It has shown remarkable success in tasks like image recognition, natural language processing, and speech recognition.
Applying Machine Learning to Real-world Problems
Machine learning finds applications in various industries and domains. LSI Keywords: healthcare, finance, recommendation systems.
Question 14: How is Machine Learning Used in Healthcare?
Machine learning is transforming the healthcare sector by aiding in disease diagnosis, drug discovery, personalized treatment plans, and medical image analysis.
Question 15: What Role Does Machine Learning Play in Finance?
In finance, machine learning is employed for fraud detection, credit risk assessment, algorithmic trading, and customer service improvement.
Question 16: How Do Recommendation Systems Work?
Recommendation systems utilize machine learning algorithms to suggest products, movies, or content based on users' preferences and behavior, enhancing user experience.
Conclusion
Congratulations! You have completed the NPTEL Introduction To Machine Learning Week 1 Assignment Answer for 2023. This assignment is a fantastic introduction to the world of machine learning, and by mastering the concepts covered here, you are well on your way to becoming a proficient data scientist.
Remember to continue exploring and practicing your skills, as machine learning is a dynamic and ever-evolving field. Embrace the challenges and opportunities it presents, and keep nurturing your passion for artificial intelligence and data analysis